| Team Members: | Julia Baum1, Cynthia Cook2, Michael Curtis3, Joshua Edgerton4, and Scott Rabidoux5 |
| Graduate Assistant: | Andrew Raim3 |
| Faculty Mentor: | Nagaraj Neerchal3 |
| Client: | Robert Bell6 |
1Worcester Polytechnic Institute, Worcester, MA
2Catawba College, Salisbury, NC
3University of Maryland, Baltimore County, Baltimore, MD
4Cornell University, Ithaca, NY
5Wake Forest University, Winston-Salem, NC
6AT&T Bell Labs, Florham Park, NJ

Team 2, from left to right: Scott Rabidoux, Cynthia Cook, Julia Baum, Michael Curtis, Joshua Edgerton
Working with Dr. Robert Bell of AT&T labs and our mentor Dr. Nagaraj Neerchal, we worked for 8 weeks at the UMBC High Performance Computing REU. Our five person team of computer scientists and mathematicians explored the problem of improving the performance of two algorithms used to model the recommender systems used by Netflix in the way they recommend movies to users. Mainly, our task was to explore different means of parallelizing the algorithms, testing them over several data sets, and the pros and cons of each method, whether the task was feasible, etc. Over our summer at UMBC, we were able to reconstruct the two algorithms to fit the parameters of the models, test them on a serial processor, and we began the process of exploring parallelization although we were not able to fully explore the idea due to time. However, Michael Curtis continues to explore and research the problem.
Abstract:
Recommender systems are emerging as important tools for improving customer satisfaction by mathematically predicting user preferences. Several major corporations including Amazon.com and Pandora use these types of systems to suggest additional options based on current or recent purchases. Netflix uses a recommender system to provide its customers with suggestions for movies that they may like, which are based on their previous ratings. In 2006, Netflix released a large data set to the public and offered one million dollars for significant improvements on their system. In 2009, BellKor’s Pragmatic Chaos, a team of seven, won the prize by combining individual methods. Dr. Bell, with whom we collaborated, was among the winning team and provided the data set used in this project, consisting of a sparse matrix with rows of users and columns of movies. The entries of the matrix are ratings given to movies by certain users. The objective is to obtain a model that predicts future ratings a user might give for a specific movie. This model is known as a collaborative filtering model, which encompasses the average movie rating (μ), the rating bias of the user (b), the overall popularity of a movie (a), and the interaction between user preferences (p) and movie characteristics (q). Two methods, Alternating Least Squares and Stochastic Gradient, were used to estimate each parameter in this nonlinear regression model. Each method fits characteristic vectors for movies and users to the existing data. The overall focus of this project is to explore the two methods, and to investigate the suitability of parallel computing utilizing the cluster Tara in the UMBC High Performance Computing Facility.
Brief Introduction to the Problem:
Collaborative Filtering systems have had growing interest recently due to the Netflix Million Dollar Challenge to improve its existing algorithm for recommending movies. Netflix wanted to enhance the method with which they recommend movies to their users. This method would be based on prior movies the users have rated. The challenge is to be able to develop a model that predicts as accurately as possible what any particular user would rate a movie. Ideally, this could be simply interpreted as a regular linear regression; finding a model which relates the characteristics of the movies with those preferred by the user to develop an estimated rating of the user. However, the problem is quite challenging when we are dealing with sparse data, i.e. some users have rated many movies, others hardly any, and no user has rated all of the movies, let alone a significant fraction. Collaborative filtering aims to make use of the sparse data that we do have in order to best approximate the parameters of our model. However, the Netflix challenge has already been conquered. Due to the size of the data given (the actual Netflix competition data is to the order of billions of entries and sparse) modeling the problem is computationally expensive. We believe that the iterative methods on the algorithms presented can be modified and parallelized to become significantly more efficient.
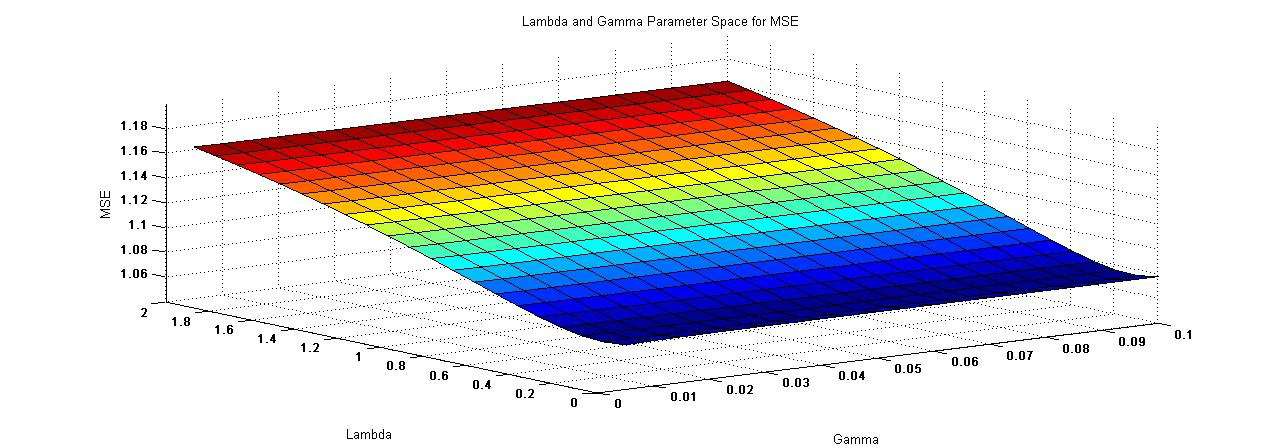
The Recommender Model and Fitting the parameters:
The model is a variation of a linear regression model using several parameters to predict each users rating for any particular movie. The aim of the model is to have the smallest mean squared error between the predictors and realized values of the movie ratings by any particular user. The full model comes from Dr. Bob Bell and Dr. Y Yoren’s paper on their prize-winning methods for the Netflix Problem.
r = u + a + b + pq
The model has a estimator rating r which is determined by a global average of ratings that we already have u, a user and movie bias b a respectively which is the amount that that movie has been above or below the average compared to other users (or movies) and to characteristic vectors p q of a specified length corresponding to a rating of how the user likes a certain characteristic, as the same element inq gives a rating for amount that the movie possesses this quality.
We used two different algorithms to find each “a, b, p, q” for the corresponding users and movies with the criterion based that we are minimizing the summation of the error over all observations, mainly Σ(r*-r) for all r,r* in our data set, where r* is the actual rating and r is our predictor. The two algorithms, stochastic gradient descent and alternating least squares both proved efficient and effective in fitting the parameters in serial over small enough data sets; however, we immediately saw the need for parallelization of the algorithms as we approached data sets in the magnitude of millions of entries, even with the tara facilities at our disposal. It became extremely time consuming to continually run the models to find a fit and a need for parallelization became clear. Although during the summer weeks we weren’t able to fully look-into parallel algorithms, through our preliminary work it was clear that the alternating least squares algorithm was ’embarrassingly parallel’ and that the problem was definitly worth exploring more.
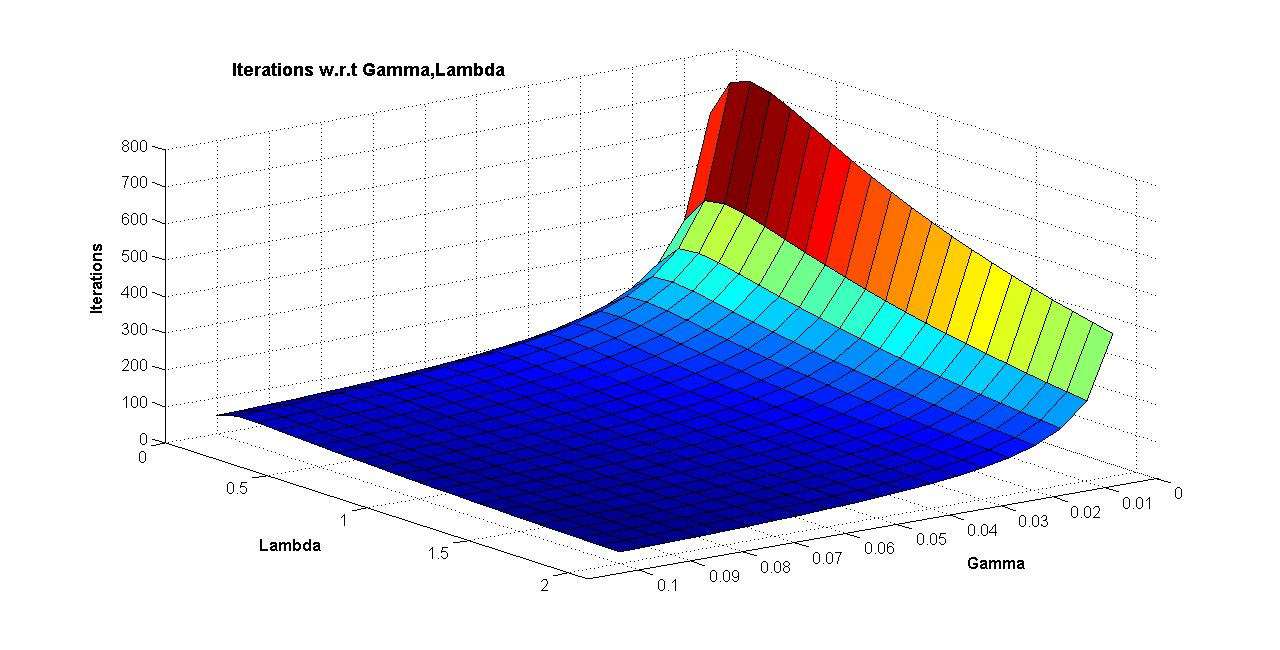
Further Work:
The single most important piece of work that we hope to accomplish is running and testing the parallel algorithms. Further testing would allow us a better mean of comparing the two methods, more thoroughly evaluate the models strengths and weaknesses, and to have a backdrop to compare our results not only to each other, but to actual results from past participants of the Netflix Competition. Several modifications to the SGD algorithm are possible with more time, such as adaptive learning rates and parameter specific gamma and lambda parameters. We might also explore several modifications of the ALS and SGD algorithms such that the parallel implementations are superior in testing results to the literal parallel implementations. For example, the actual parallelized serial algorithm for SGD is cumbersome and seems inefficient. However, with several modifications it appears really appealing and would warrant serious consideration and testing.
Links
Julia Baum, Cynthia Cook, Michael Curtis, Joshua Edgerton, Scott Rabidoux, Andrew Raim, Nagaraj Neerchal, and Robert Bell. Parallelization of Matrix Factorization for Recommender Systems. Technical Report HPCF-2010-22, UMBC High Performance Computing Facility, University of Maryland, Baltimore County, 2010. Reprint in HPCF publications list